2020 ICLR Inductive Matrix Completion Based on Graph Neural Networks
Implement code IGMC
本文提出了一种基于归纳图的矩阵完成(IGMC)模型,它不使用任何边信息,通过将(评级)矩阵分解为行(用户)和列(物品)的低维潜在嵌入的乘积。 IGMC 训练一个图神经网络 (GNN),它完全基于从评分矩阵生成的(用户、项目)对周围的 1 跳子图,并将这些子图映射到它们相应的评分。
该工作表明:
- 可以在不使用辅助信息的情况下训练归纳矩阵完成模型,同时获得与最先进的转导方法相似或更好的性能;
- 围绕(用户,项目)对的局部图模式是该用户对项目的评价的有效预测器;
- 建模推荐系统可能不需要长期依赖。
1 .IGMC
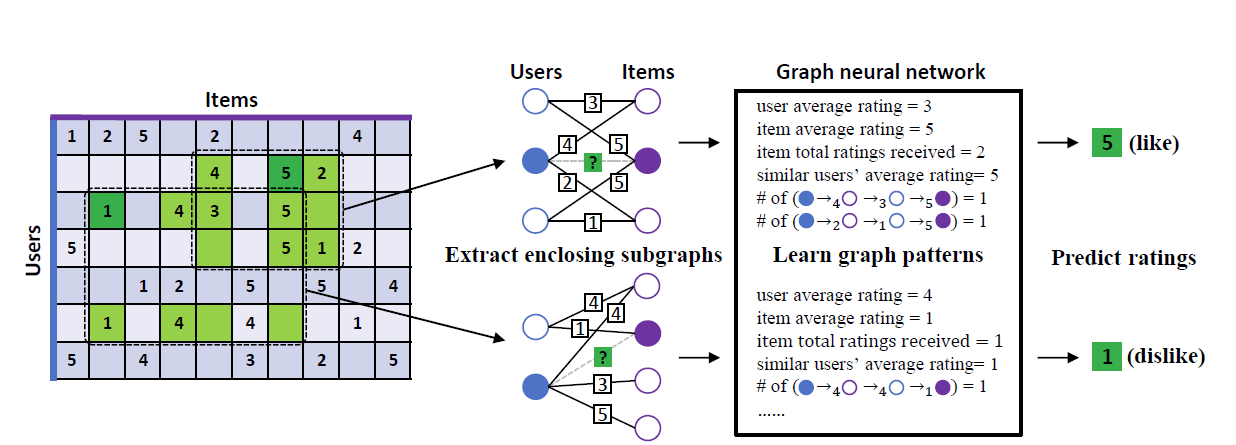
如图1,IGMC围绕每个评分(深绿色)提取局部封闭子图,并训练 GNN 将子图映射到评分。 每个封闭子图由与目标评分相关联的用户和物品以及它的$h$-跳邻居(这里 h=1)诱导。 从子图中,GNN 可以学习对评级预测有用的混合图模式(例如平均评级、路径等)。 最后使用经过训练的 GNN 来补全缺失的条目。
| 符号 | 表示 | 解释 |
|---|---|---|
| $\mathrm{R}$ | 评分矩阵 | |
| $G$ | 无向二部图 | 从给定的评分矩阵$\mathrm{R}$构造,节点为用户$u$或者物品$v$ |
| $u$ | 用户 | $G$中的节点,$\mathrm{R}$一行 |
| $v$ | 物品 | $G$中的节点,$\mathrm{R}$中的一列 |
| $(u,v)$ | 图中的边 | 只有用户和物品之间有边,用户与用户、物品与物品之间没有边 |
| $r=\mathrm{R}_{u,v}$ | 边$(u,v)$的值 | 表示用户$u$给物品$v$的评分 |
| $R$ | 所有可能分数的集合 | |
| $N_{r}(u)$ | 用户$u$的所有邻居集合 | 通过类型为$r$的边连接到$u$ |
1.1 ENCLOSING SUBGRAPH EXTRACTION 提取封闭子图
首先,对于每个观察到的评分$\mathrm{R}_{u,v}$,从$G$中提取一个围绕$(u,v)$的$h$-跳的封闭子图。算法 1 描述了用于提取$h$-跳封闭子图的 BFS过程。

这些封闭的子图将提供给 GNN 并对其评分进行回归。 然后,对于每个测试$(u,v)$对,再次从$G$中提取其$h$-跳封闭子图,并使用经过训练的GNN模型来预测其评分。需要注意的是,在为$(u,v)$提取训练封闭子图后,应该删除边$(u,v)$,因为它是要预测的目标。
1.2 NODE LABELING 节点标注
IGMC 的第二部分是节点标注。 在将封闭子图提供给 GNN 之前,首先对其应用节点标注,为子图中的每个节点提供一个整数标签。目的是使用不同的标签来标记节点在子图中的不同角色。 理想情况下的节点标签应该能够:
- 区分目标用户和目标评分所在的目标物品;
- 区分用户类型节点和物品类型节点。
否则,GNN 无法区分哪个用户和物品来预测评分,并且可能会丢失节点类型信息。
为了满足这些条件,提出了如下的节点标签方法:
- 分别为目标用户和目标物品赋予标签 0 和 1;
- 根据算法 1 中子图中包含的其他节点的标签来确定其他节点的标签:
- 如果第 i 跳包含一个用户类型节点,给予标签$2i$;
- 如果第 i 跳包含一个项目类型节点,给予标签$2i+1$。
这样的节点标记可以充分区分:
- 目标节点与“上下文”节点;
- 用户与物品(用户总是有偶数标签);
- 与目标评分不同距离的节点。
当送到 GNN 时,这些节点标签的 one-hot 编码将被视为子图的初始节点特征$x^{0}$。节点标签完全在每个封闭子图中确定,因此独立于全局二部图。 给定一个新的封闭子图,即使它的所有节点都来自不同的二部图,也可以预测它的评分,因为 IGMC 纯粹依赖于局部封闭子图中的图模式,而没有利用任何特定于二部图的全局信息。
1.3 GRAPH NEURAL NETWORK ARCHITECTURE 图神经网络架构
IGMC 的第三部分是训练图神经网络 (GNN) 模型,从封闭的子图中预测评分。 IGMC 将图级 GNN 应用于$(u,v)$周围的封闭子图,并将子图映射到评分。因此,GNN 中有两个组件:
- 消息传递层,为子图中的每个节点提取特征向量;
- 一个池化层,用于从节点特征中总结子图表示。
为了学习不同边类型引入的丰富图模式,我们采用关系图卷积算子(R-GCN)作为 GNN 的消息传递层,其形式如下:
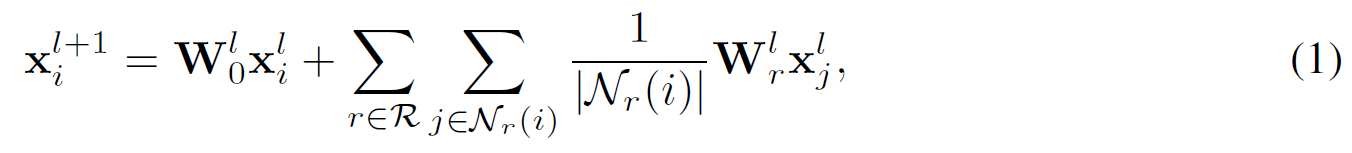
| 符号 | 表示 |
|---|---|
| $x_{i}^{l}$ | 节点$i$在第$l$层的特征向量 |
| $ W_{0}^{l},\lbrace W_{r}^{l},r\in R\rbrace $ | 可学习的参数矩阵 |
由于连接到$i$的具有不同边类型$r$的邻居$j$由不同的参数矩阵$W_{r}^{l}$处理,所以能够在边类型内部学习大量丰富的图模式,例如目标用户对物品的平均评分,目标物品接收到的平均评分,以及两个目标节点通过哪些路径连接等。
堆叠$L$个消息传递层,并在两层之间用$tanh$激活。节点$i$来自不同层的特征向量被连接起来作为其最终表示$h_{i}$:
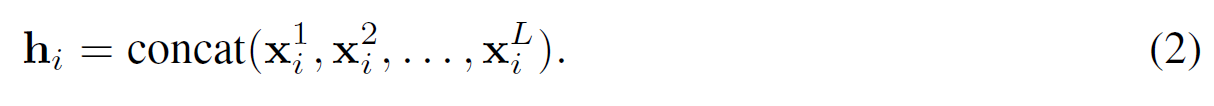
接下来,将节点表示池化为图级特征向量。 在这项工作中,使用一个不同的池化层连接目标用户和目标物品的最终表示来作为图形表示:

其中,$h_{u},h_{v}$分别代表目标用户和目标物品的最终表示。这样选择是由于这两个目标节点与其他上下文节点相比具有额外的重要性。
在获得最终的图形表示后,使用 MLP 来输出预测的评分:

其中,$W,w$是$MLP$的参数,将图形表示$g$映射到标量评分$\hat{r}$;$\sigma$是激活函数($ReLU$)。
1.4 MODEL TRAINING 模型训练
Loss Function
最小化预测和真实评分之间的均方误差 (MSE):
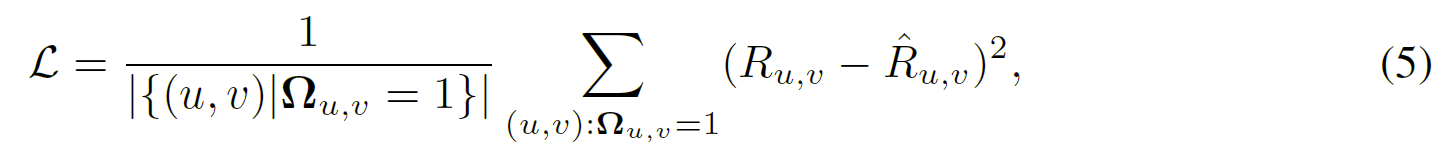
其中,$R_{u,v},\hat{R}_{u,v}$分别表示$(u,v)$的真实评分和预测评分;$\Omega$是一个 0/1 掩码矩阵,表示评分矩阵$\mathrm{R}$的观察项。
Adjacent Rating Regularization
GNN 中使用的 R-GCN 层针对不同的评级类型具有不同的参数$W_{r}$。 这里的一个缺点是它没有考虑评级的大小。 例如,MovieLens 的评分 4 和评分 5 都表示用户喜欢这部电影,而评分 1 表示用户不喜欢这部电影。理想情况下,希望模型意识到 4 比 1 更类似于 5 的事实。 然而在 RGCN 中,评级 1、4 和 5 仅被视为三种独立的边缘类型——评级的大小和顺序信息完全丢失。
为了解决这个问题,提出了一种相邻评级正则化 (ARR) 技术,该技术鼓励彼此相邻的评级具有相似的参数矩阵。假设$R$中的评分表现出一个排序$r_{1},r_{2},…,r_{|R|}$,这表明用户对物品的偏好越来越高。因此,ARR正则化为:
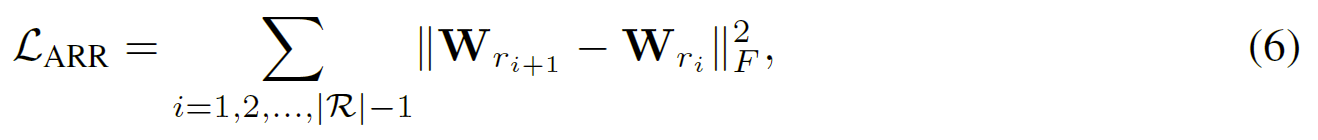
其中,$||\cdot||_{F}$表示矩阵的 Frobenius 范数。
上述正则化器抑制了相邻评分的参数矩阵差异过大,这不仅考虑了评分的顺序,而且还通过从相邻评分中转移知识来帮助优化那些不频繁的评分。
最终的损失函数由下式给出:

$\lambda$在MSE损失和ARR正则化之间进行平衡。
2. 实验
对所有数据集使用 1 跳封闭子图,并发现它们足够好。 虽然使用 2 跳或更多跳可以稍微提高性能,但需要更长的训练时间。