KDD 2020 | Handling Information Loss of Graph Neural Networks for Session-based Recommendation
Handling Information Loss of Graph Neural Networks for Session-based Recommendation (github.com)
最近,图神经网络(GNN)因其在各种应用中令人信服的性能而越来越受欢迎。许多先前的研究也尝试将 GNN 应用于基于会话的推荐并获得了可喜的结果。然而,这些基于 GNN 的基于会话的推荐方法存在两个信息丢失问题:
-
有损会话编码问题
由于从会话到图的有损编码以及消息传递期间的置换不变聚合,一些关于物品转换的顺序信息被忽略。
提出了一种无损编码方案和一个基于 GRU 的边缘顺序保留聚合层,专门设计用于处理无损编码的图。
-
无效的远程依赖捕获问题
由于层数有限,无法捕获会话中的某些远程依赖项。
提出了一个快捷图注意层,它通过沿着快捷连接传播信息来有效地捕获远程依赖关系。
通过结合这两种层,能够构建一个没有信息丢失问题的模型,并且在三个公共数据集上的表现优于最先进的模型。提出了一种新的 GNN 模型,称为 LESSR(基于会话的推荐的无损边序保留聚合和快捷图注意)。
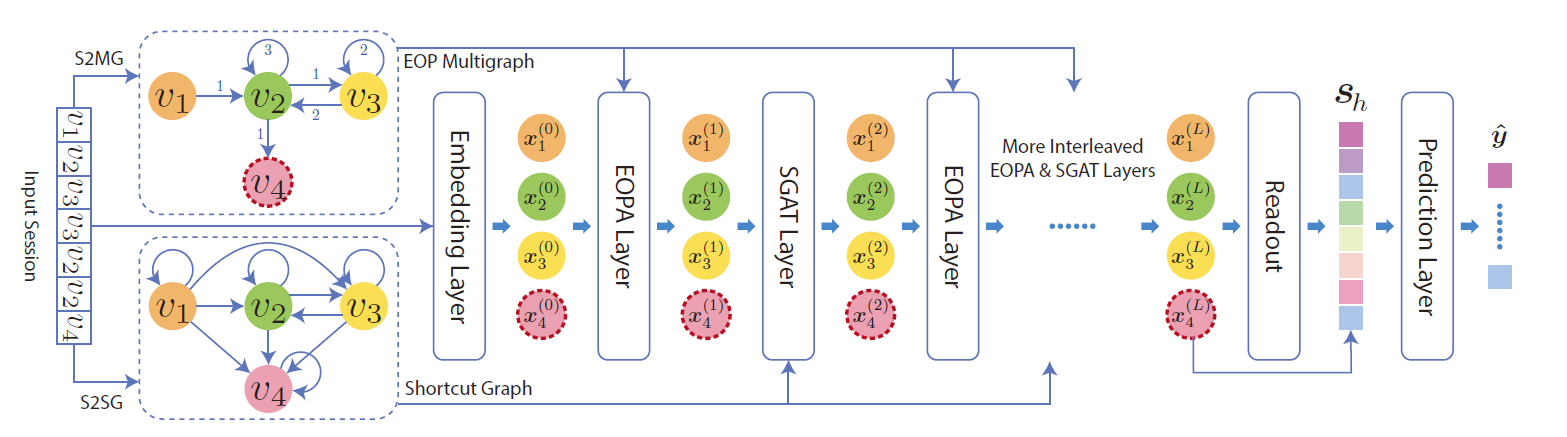
图2说明了 LESSR 的工作流程。 给定的输入会话首先被转换为称为边序保留 (EOP) 多重图的无损编码图和快捷图,其中 EOP 多重图可以解决有损会话编码问题,快捷图可以解决无效的远程依赖捕获问题 . 然后,将图与物品嵌入一起传递到多个边序保留聚合 (EOPA) 和快捷图注意 (SGAT) 层以生成所有节点的潜在特征。 EOPA 层使用 EOP 多重图捕获本地上下文信息,SGAT 层使用快捷图有效地捕获远程依赖关系。 然后,应用带有注意力的读出函数从所有节点嵌入生成图级嵌入。 最后,我们将图级嵌入与用户最近的兴趣相结合来提出建议。
1. GNN
GNN 是直接对图数据进行操作的神经网络。 它们用于学习任务,例如图分类、节点分类和链接预测问题。 在本文中,只关注图分类问题,因为基于会话的推荐可以表述为这样的问题。
令$G=(V,E)$为给定的图,$V,E$分别代表节点集和边集,每个节点$i\in V$与一个节点特征向量$x_{i}$相连,该特征向量会传递给GNN的第一层作为初始的节点表示。大多数 GNN 可以从消息传递的角度来理解。 在 GNN 的每一层中,节点表示通过沿边传递消息来更新。 该过程可以表述如下:
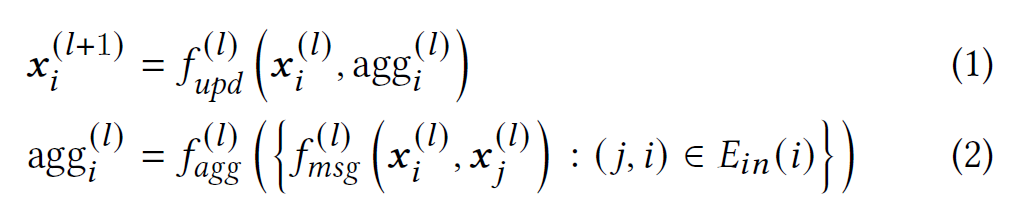
| 符号 | 表示 | 解释 |
|---|---|---|
| $x_{i}^{(l)}$ | 节点$i$在第$l$层的表示 | |
| $E_{in}(i)$ | 节点$i$的传入边的集合 | |
| $f_{msg}^{(l)}$ | 信息函数 | 计算要从相邻节点传播到目标节点的消息 |
| $f_{agg}^{(l)}$ | 聚合函数 | 聚合传递给目标节点的信息 |
| $f_{upd}^{(l)}$ | 更新函数 | 根据原始节点表示和聚合信息计算新节点表示 |
令$L$为 GNN 中的层数。 在$L$层的$L$步消息传递之后,最终的节点表示捕获了有关图结构和$L$跳邻域内节点特征的信息。 对于图分类任务,读出函数$f_{out}$用于通过聚合最后一层中所有节点的表示来生成图级别表示$h_{G}$:
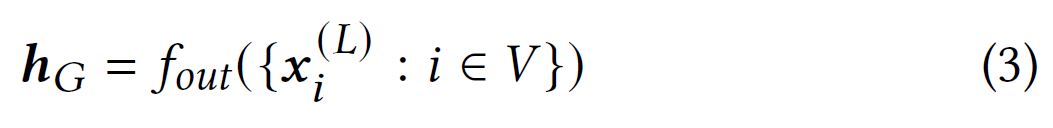
2. 论文模型
提出的方法涉及两个主要组成部分:
- 将每个输入会话转换为边序保留 (EOP) 多图和快捷图的模块,因为 GNN 模型需要两种类型的图作为输入(第 2.2 节);
- 提出的 GNN 模型 LESSR(第 2.3 节)。
2.1 问题定义
基于会话的推荐是next-item推荐的一个例子。 它的目标是在给定活动会话中已经点击的一系列物品的情况下推荐用户最有可能点击的物品。给定通用物品集合$I=\lbrace v_{1},v_{2},…,v_{|I|}\rbrace$,一组会话$s_{i}=[s_{i,1},s_{i,2},…,s_{i,l_{i}}]$是按时间排序的物品序列,$s_{i,t}\in I$是在时间步长$t$下的物品,$l_{i}$是$s_{i}$的长度。模型的目标是预测下一个物品$s_{i,l_{i+1}}$。典型的基于会话的推荐系统生成下一个物品的概率分布,$p(s_{i,l_{i+1}}|s_{i})$。具有最高概率的物品在推荐的候选集中。
本文中不考虑额外的上下文信息,例如用户 ID 和物品属性。 物品 ID 嵌入在 3 维空间中,并作为模型中的初始物品特征。 这是基于会话的推荐文献中的常见做法。 然而,很容易调整我们的方法以考虑额外的上下文信息。 例如,用户 ID 嵌入可以作为图形级别的属性,并且可以附加到每层中的物品 ID 嵌入。物品特征可以与物品 ID 嵌入结合或替换。
2.2 将会话转换为图
要使用 GNN 处理会话,必须先将会话转换为图。 在本小节中,首先介绍一种将会话转换为 EOP 多图的称为 S2MG 的方法,然后介绍另一种将会话转换为快捷图的称为 S2SG 的方法。
2.2.1 S2MG: Session to EOP Multigraph
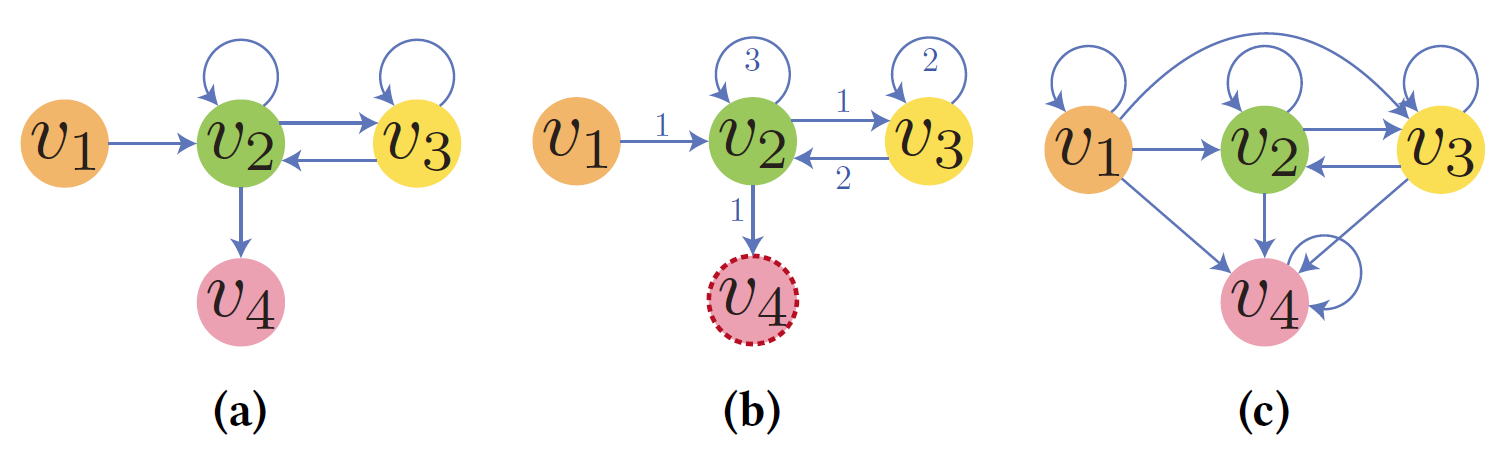
我们提出了一种称为 S2MG(会话到 EOP 多重图)的方法,它将会话转换为保留边顺序的有向多重图。对于原始会话中的每个转移$u\to v$,创建一条边$(u,v)$。该图是一个多重图,因为如果从$u$到$v$有多个转换,则会创建从$u$到$v$的多条边。然后,对于每个节点$v$,$E_{in}(v)$中的边可以按照它们在会话中出现的时间进行排序。通过给$E_{in}(v)$中的每条边一个整数属性来记录顺序,该属性表示它在$E_{in}(v)$中的边之间的相对顺序。首先出现在$E_{in}(v)$的边被赋予 1,下一个边被赋予 2,依此类推。例如,会话$s_{1}=[v_{1},v_{2},v_{3},v_{3},v_{2},v_{2},v_{4}]$被转换为图 3(b) 中的图形,用$MG_{s1}$表示。为了使转换真正无损,我们还标记了最后一项,例如会话$s_{1}$的节点$v_{4}$,用虚线圆圈表示。将此结果图称为给定会话的边序保留 (EOP) 多重图。
2.2.2 S2SG: Session to Shortcut Graph
为了处理现有基于 GNN 的基于会话的推荐模型中无效的远程依赖问题,提出了将在第 2.3.2 节中描述的快捷图注意力(SGAT)层。 SGAT 层需要一个不同于上述 EOP 多重图的输入图。 输入图是使用以下称为 S2SG(会话到快捷图)的方法从输入会话转换而来的。
给定一组会话$s_{i}$,创建一个图,其节点是$s_{i}$中的唯一项。 对于每对有序的节点$(u,v)$,当且仅当存在一对$(s_{i,t_{1}},s_{i},t_{2})$,创建从$u$到$v$的边,使得$s_{i,t_{1}}=u,s_{i,t_{2}}=v,t_{1}<t_{2}$,该图被称为快捷图,因为它无需通过中间物品即可连接物品。还在图中添加了自循环,以便稍后在 SGAT 层执行消息传递时,可以将更新函数和聚合函数结合起来,这是 GAT 模型中的常见做法。因此,$s_{1}=[v_{1},v_{2},v_{3},v_{3},v_{2},v_{2},v_{4}]$的快捷图就是图3(c) 所示的图形。
在 2.3.2 节中,将展示 SGAT 层如何通过在快捷图上执行消息传递来解决无效的远程依赖问题。
2.3 GNN Model: LESSR
本小节将详细介绍 GNN 模型 LESSR,其概述如图 2 所示。首先,在 2.3.1 节中介绍了 EOPA 层,在 2.3.2 节中介绍了 SGAT 层。 接下来,在第 2.3.3 节中描述如何堆叠这两种类型的层。 接下来,在第 2.3.4 节中展示如何获取会话嵌入。 最后,在第 2.3.5 节中给出了如何进行预测和训练。
2.3.1 Edge-Order Preserving Aggregation (EOPA) Layer
鉴于从会话无损转换的 EOP 多图,GNN 仍然需要正确处理这些图,以便不同的会话可以映射到不同的表示。 这在现有的基于 GNN 的基于会话的推荐模型中是不可能的,因为它们使用置换不变的聚合函数,而忽略了边的相对顺序。 因此,这些模型只适用于边之间的排序信息不重要的数据集,这意味着它们的建模能力存在限制。 为了填补这一空白,提出了边缘顺序保留聚合 (EOPA) 层,该层使用 GRU 聚合从相邻节点传递的信息。
令$OE_{in}(i)=[(j_{1},i).(j_{2},i),…,(j_{d_{i}},i)]$是$E_{in}(i)$中边的有序列表,其中$d_{i}$是节点$i$的入度。$OE_{in}(i)$可以通过使用 EOP 多重图中边的整数属性从$E_{in}(i)$获得。来自邻居的聚合信息定义如下:
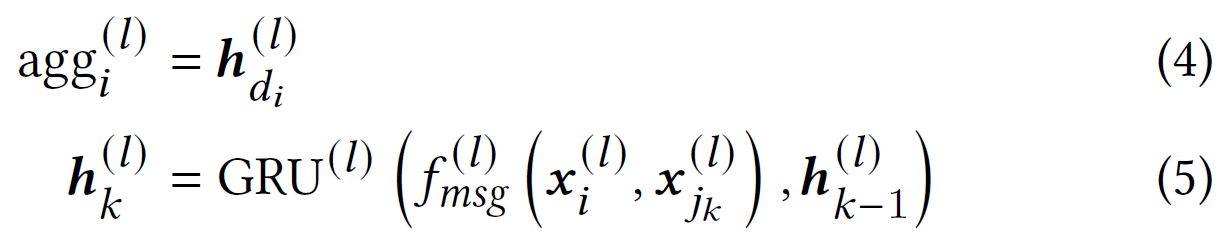
GRU 聚合器是一种 RNN 聚合器。 选择 GRU 而不是 LSTM,因为 GRU 在基于会话的推荐任务上优于 LSTM。 尽管在现有工作中已经提出了 RNN 聚合器,但应该注意的是,这些 RNN 聚合器的工作方式与我们的不同。具体来说,现有的 RNN 聚合器通过对这些边的随机排列执行聚合来故意忽略传入边的相对顺序,而我们的 GRU 聚合器以固定顺序执行聚合。 这是因为在基于会话的推荐设置中,边自然是按时间排序的。 但是,我们需要强调的是 GRU 聚合器不是我们的主要贡献。 我们的主要贡献是应用 GRU 聚合器来解决第 2.2 节中描述的信息丢失问题。
来自现有 GNN 模型的相同消息和更新函数可以与 GRU 聚合器一起使用,但是,考虑到 GRU 强大的表达能力,简单地对消息和更新函数使用线性变换。 因此,将所有内容放在一起,模型的 EOPA 层定义如下:
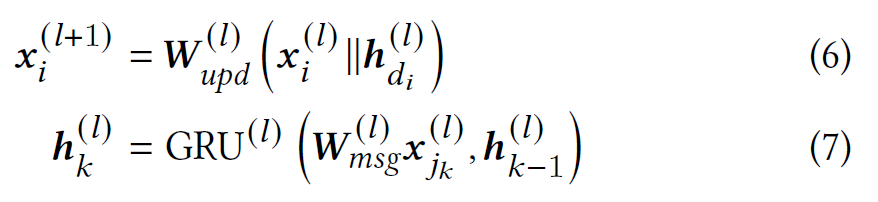
2.3.2 Shortcut Graph Attention (SGAT) Layer
一般来说,每一层都将信息传播一步,因此一层只能捕获节点之间的一跳关系。为了捕获多跳关系,可以堆叠多个 GNN 层。不幸的是,这会引入过度平滑问题,即节点表示收敛到相同的值。由于过度平滑问题通常发生在层数大于 3 时,因此堆叠多个层并不是捕获多跳关系的好方法。此外,即使可以堆叠多个层,GNN 也只能捕获最多$k$跳关系,其中 : 等于层数。但是,在电子商务网站等实际应用中,会话长度大于 : 的情况很常见。因此,现有的基于会话的推荐 GNN 模型不能有效地捕获很长范围内的依赖关系。为了解决这个问题,我们提出了快捷图注意力(SGAT)层,它本质上是利用 S2SG 获得的快捷图中的边进行快速信息传播。
具体来说,SGAT 层使用以下注意机制沿快捷图中的边传播信息。
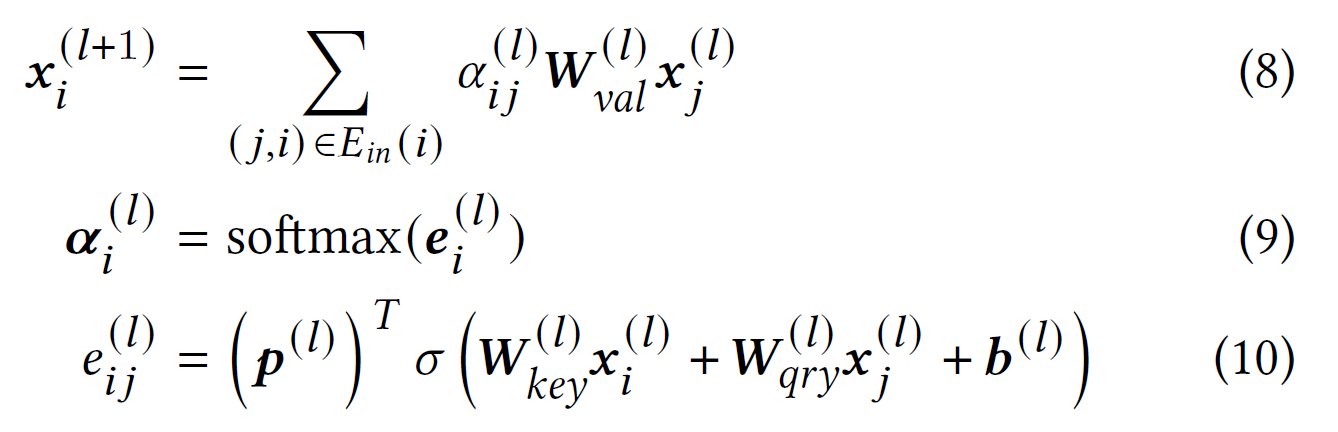
快捷图中的边直接将每个物品与其所有后续物品连接起来,而无需经过中间物品。 因此,快捷图中的边可以看作是物品之间的“快捷连接”。 SGAT 层可以有效地捕获任何长度的长期依赖关系,因为它在一步中沿着物品之间的快捷连接传播信息,而无需经过中间物品。 它可以与现有基于 GNN 的方法中的原始层相结合,以提高它们捕获远程依赖项的能力。
2.3.3 Stacking Multiple Layers
EOPA 层和 SGAT 层被提出来解决之前基于 GNN 的基于会话的推荐方法的两个信息丢失问题。 为了构建一个没有信息丢失问题的 GNN 模型,我们堆叠了多个 EOPA 和 SGAT 层。 我们不是将所有 EOPA 层放在所有 SGAT 层之后,反之亦然,而是出于以下原因将 EOPA 层与 SGAT 层交错:
- 快捷图是原始会话的有损转换,因此连续堆叠多个SGAT层会引入有损会话编码问题。 SGAT 层越多,问题就越严重,因为信息丢失量会累积。 通过交错 EOPA 和 SGAT 层,丢失的信息可以保留在后续的 EOPA 层中,SGAT 层可以只专注于捕获远程依赖关系。
- 交织两种层的另一个优点是每种层都可以有效地利用另一种层捕获的特征。 由于 EOPA 层更能捕获局部上下文信息,SGAT 层更能捕获全局依赖,因此将两种层交错可以有效地结合两者的优点,提高模型学习更复杂依赖的能力。
为了进一步促进特征重用,引入了密集连接。 每一层的输入由所有先前层的输出特征组成。 具体来说,原来第$l$层的输入是$\lbrace x_{i}^{(l-1)}:i\in V\rbrace$。通过密集连接,第$l$层的输入变为$\lbrace x_{i}^{(0)}||x_{i}^{(1)}||…||x_{i}^{(l-1)}:i\in V\rbrace$,这是所有先前层的输出的串联。
结果表明,具有密集连接的深度学习模型参数效率更高,即以更少的参数实现相同的性能,因为每个较高层不仅可以使用其前一层的抽象特征,还可以在较低层使用低级特征。
2.3.4 Generating Session Embedding
在所有层的消息传递完成后,可以得到所有节点的最终表示。 为了将当前会话表示为嵌入向量,应用了一个读出函数,该函数通过使用注意机制聚合节点表示来计算图级表示。令$x_{last}^{(L)}$为会话中最后一项的最终节点表示。则图层次的表示$h_{G}$定义为:
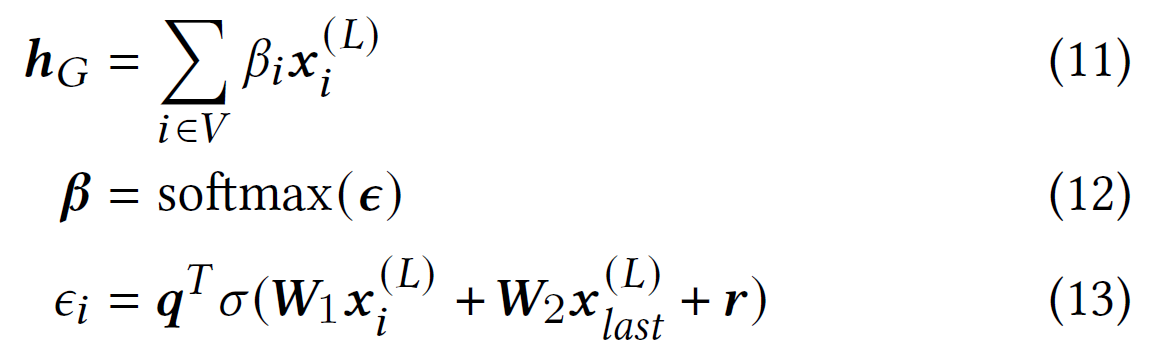
图级表示可以捕获当前会话的全局偏好,表示为$s_{g}=h_{G}$。因为明确考虑用户最近的兴趣也很重要,定义了一个局部偏好向量$s_{l}=x_{last}^{(L)}$。然后,将会话嵌入计算为全局和本地会话首选项的线性变换:

2.3.5 Prediction and Training
获得会话嵌入后,可以使用它通过计算下一个物品的概率分布来做出推荐。对于每个物品$i\in I$,首先使用其嵌入$v_{i}$的会话嵌入计算得到一个分数:

然后,可以计算下一个物品为$i$的预测概率:
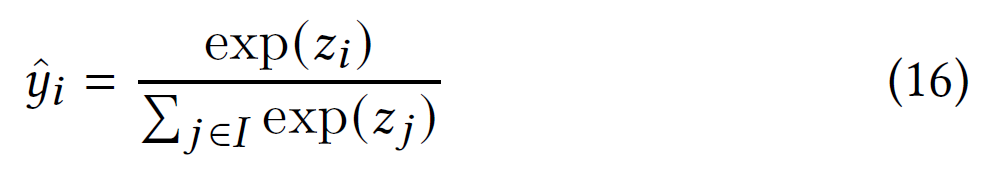
对于top-K推荐,可以只推荐具有最高概率的物品。
令$y$表示下一项的真实概率分布,它是一个独热向量。 损失函数被定义为预测和真实情况的交叉熵:
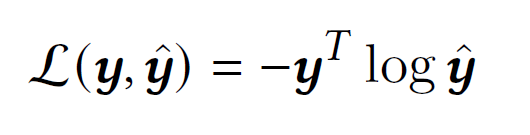
然后,所有参数以及物品嵌入都被随机初始化并在端到端的反向传播训练范式中共同学习。