SSE-PT: Sequential Recommendation Via Personalized Transformer
时间信息对于推荐问题至关重要,因为用户偏好在现实世界中自然是动态的。 深度学习的最新进展,尤其是除了在自然语言处理中广泛使用的 RNN 和 CNN 之外,还发现了各种注意力机制和更新的架构,可以更好地利用每个用户参与的物品的时间顺序。 特别是 SASRec 模型,受到自然语言处理中流行的 Transformer 模型的启发,取得了最先进的结果。 然而,SASRec 就像最初的 Transformer 模型一样,本质上是一个非个性化的模型,不包括个性化的用户嵌入。
为了克服这个限制,本文提出了一种个性化变换器 (SSE-PT) 模型,不仅更具可解释性,而且能够关注每个用户最近的参与模式。 此外, SSE-PT 模型稍加修改,称之为 SSE-PT++,可以处理极长的序列,并在具有可比训练速度的排名结果方面优于 SASRec,在性能和速度要求之间取得平衡。
1. 论文模型
1.1 序列推荐
给定 n 个用户,每个用户按时间顺序与 m 个物品的一个子集互动,顺序推荐的目标是在任何给定时间点为任何给定用户学习在总共 m 个物品中前 K 个物品的良好个性化排名。假设数据为 n 个物品序列的格式:
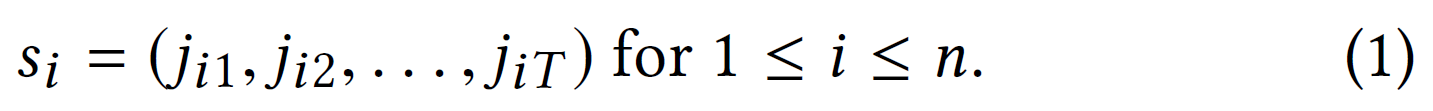
长度为 T 的序列$s_{i}$包含用户 i 按照时间顺序(从旧到新)与之交互的最后 T 个物品的索引。 对于不同的用户,序列长度可能会有所不同,但可以填充较短的序列,使它们都具有长度 T 。不能简单地将数据点随机分成训练/验证/测试集,因为它们按时间顺序排列。 相反,需要确保训练数据在验证数据之前,也就是在测试数据之前。 使用序列中的最后一个物品作为测试集,倒数第二个物品作为验证集,其余的作为训练集。使用 NDCG@K 和 Recall@K 等排名指标进行评估,这些指标在附录中定义。
1.2 个性化的 Transformer 架构
模型称之为 SSE-PT,它利用了一种称为随机共享嵌入的新正则化技术。在接下来的部分中,将检查的个性化转换器 (SSE-PT) 模型的每个重要组件,尤其是嵌入层,以及随机共享嵌入 (SSE) 正则化技术的新应用。
嵌入层
定义一个可学习的用户嵌入查找表$U\in R^{n\times d_{u}}$和物品嵌入查找表$V\in R^{m\times d_{i}}$,其中$d_{u},d_{i}$分别为用户和物品的隐藏单元的数量。同时还指定了可学习的位置编码表$P\in R^{T\times d}$,其中$d=d_{u}+d_{i}$。所以每个输入序列$s_{i}\in R^{T}$将由以下嵌入表示:
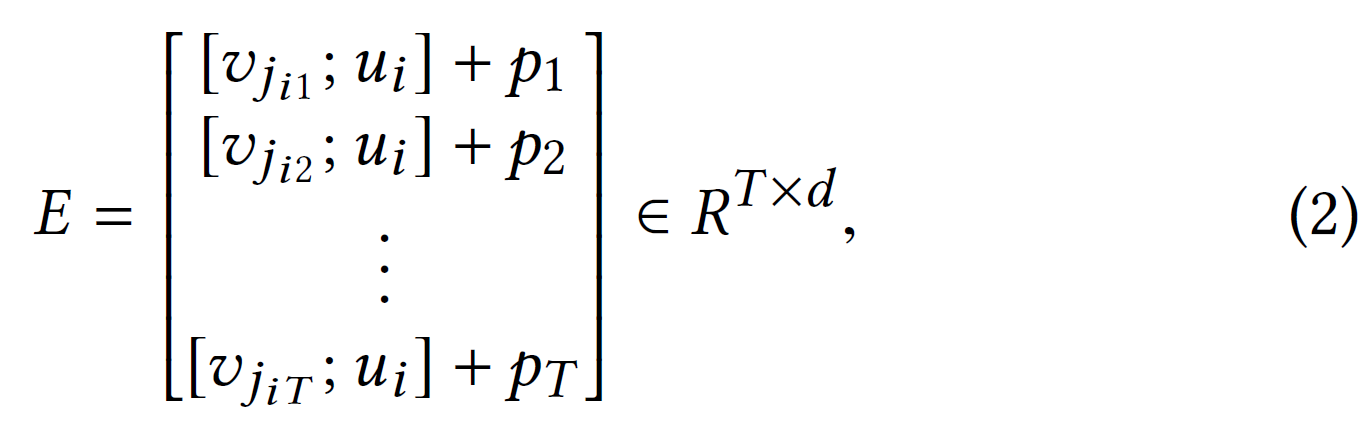
其中$[v_{j_{it}};u_{i}]$表示将物品嵌入$v_{j_{it}}\in R^{d_{i}}$和用户嵌入$u_{i}\in R^{d_{u}}$连接为时间$t$下的嵌入$E_{t}\in R^{d}$。
Transformer编码器
在嵌入层之上,我们有 B 个自注意力层和全连接层,其中每一层根据前一层的输出为每个时间步提取特征。 这部分与原始论文中使用的 Transformer 编码器相同。
预测层
在时间$t$,用户$i$参与物品$l$的预测概率为:

其中 σ 是 sigmoid 函数,$r_{itl}$是用户$i$在时间点$t$对物品$l$的预测得分,定义为:
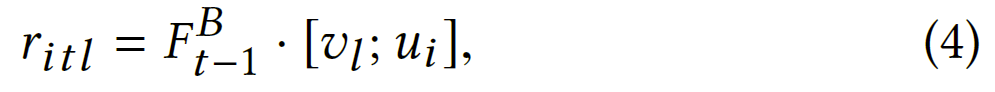
其中$F_{t-1}^{B}$是在最后一个时间戳与变压器编码器关联的输出隐藏单元。
尽管可以为$u_{i}$和$v_{l}$使用另一组用户和物品嵌入查找表,但使用与嵌入层中相同的一组嵌入查找表 U,V 更好。 但是这些嵌入的正则化可能会有所不同。 为了将(4)中的$u_{i}$和$v_{l}$与(2)中的 ui ,vj 区分开来,我们将(4)中的嵌入称为输出嵌入和(2)中的嵌入称为输入嵌入。
{正项预测概率之间的二元交叉熵损失$l=j_{i(t+1)}$和一个均匀采样的负项$k\in \Omega$,由$-[\log(p_{itl})+\log(1-p_{itk})]$给出。对 $s_{i}$和$t$求和,可以得到想要最小化的目标函数:
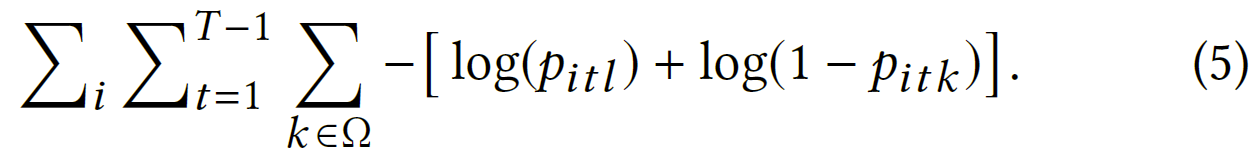
在推理时,可以通过对所有物品 ℓ 的分数$r_{itl}$进行排序并推荐排序列表中的前$K$个物品来为用户$i$在时间$t$做出前$K$个推荐。
随机共享嵌入的新应用
SSE-PT 模型最重要的正则化技术是随机共享嵌入(SSE)。 SSE 的主要思想是在 SGD 期间用另一个具有一定概率的嵌入随机替换嵌入,这具有正则化嵌入层的效果。 如果没有 SSE,所有现有的众所周知的正则化技术,如层归一化、dropout 和权重衰减都将失败,并且无法防止模型在引入用户嵌入后严重过度拟合。
1.3 处理长序列:SSE-PT++
为了处理极长的序列,可以对基本 SSE-PT 模型在输入序列$s_{i}$是如何馈送到 SSE-PT 神经网络方面进行轻微修改。将增强模型称为 SSE-PT++ 以区别于之前讨论的 SSE-PT 模型,后者无法处理长于 T 的序列。