An Efficient and Effective Framework for Session-based Social Recommendation
为了解决效率问题,本文提出了一个有效的基于会话的社交推荐框架。 在该框架中,首先,使用异构图神经网络来学习整合社交网络知识的用户和物品表示。 然后,为了生成预测,只有用户和物品表示与当前会话相关的信息被传递给非社会感知模型。 在推理过程中,由于可以预先计算用户和物品表示,因此整个模型的运行速度与原始的非社会感知模型一样快,同时可以通过利用来自社交网络的知识获得更好的性能。
除了高效之外,框架还有两个额外的优势。 首先,该框架是灵活的,因为它与任何现有的非社会感知模型兼容,并且可以轻松地整合除社交网络之外的更多知识。 其次,框架可以捕获跨会话项转换,而现有方法只能捕获会话内项转换。
1. Social-Aware Efficient Framework
在本节中,我们将介绍我们称为 SEFrame 的高效 SSR 框架。 SEFrame 具有三个组件。第一个组件从异构知识图中学习用户和物品表示。我们将此组件称为知识图谱嵌入 (KGE) 组件(第 1.1 节),因为可以将学习到的表示视为融合来自异构图中的知识的嵌入。第二个组件称为个性化会话嵌入 (PSE) 组件(第 1.2 节),将给定会话的相关用户和物品表示作为输入,并生成特定于会话的嵌入,以捕获用户当前的兴趣和物品的上下文信息。第三个组件称为预测组件(第 1.3 节),根据会话嵌入、用户嵌入和物品嵌入生成下一个物品的概率分布。
1.1 KGE组件
KGE 组件涉及两个任务。 第一个任务是从所有历史用户行为 D 和社交网络 S 构建异构知识图 K。第二个任务是使用异构图神经网络 (HGNN) 学习融合 K 知识的用户和物品表示。
将异构知识图谱表示为$K=(V,E,A,R,\phi, \psi)$,节点集$V=U\cup I$包含$D,S$中所有的用户和物品。边集$E$包含四种类型的有向边,包括用户-用户,用户-物品,物品-用户,物品-物品。重用用户和物品集的符号来表示节点和边的类型。节点类型的集合表示为$A=\lbrace U,I\rbrace$,边类型的集合表示为$R=\lbrace UU,UI,IU,II\rbrace$。每条边都有一个整数权重。$\phi:V\mapsto A$是将节点映射到其类型的函数;$\psi:E\mapsto R$是将边映射到其类型的函数。
-
用户-用户边表示用户之间的社交关系。
一条用户-用户边$(u,v)\in E$存在,如果用户$u$被用户$v$所关注。使用“被关注”而不是“关注”,因为 GNN 使用传入边更新节点表示,并且用户受他们所关注的用户的影响比关注他们的用户更多。 用户-用户边的权重定义为 1。
-
用户-物品边、物品-用户边表示用户和物品之间的交互。
如果用户$u$在某些会话中点击了物品 𝑖,则存在用户-物品边$(u,i)$和物品-用户边$(i,u)$在$E$中。这两条边中每条边的权重被定义为交互发生的次数。
-
物品-物品边表示物品之间的交互。
如果在任何会话中存在从$i$到$j$的转移,则存在物品-物品边$(i,j)\in E$。此边的权重是转移发生的次数。
获得异构知识图谱后, 第二个任务是应用 HGNN 来学习用户和物品的表示,其中用户表示捕获用户偏好和社会影响,物品表示从用户-物品交互和跨会话物品转移模式中捕获协作信息。将以上的表示称为知识图谱嵌入(KG 嵌入)。
1.2 PSE组件
KG 嵌入捕获所有会话和整个社交网络中的全局知识,而不捕获特定于会话的上下文信息。 然而,在 SR 中,当前会话 𝑆 中的用户行为对于捕捉用户的动态兴趣很重要。 因此,PSE 组件会生成个性化的会话特定嵌入,以捕获用户当前的偏好和物品的上下文属性。 它涉及两个任务:
-
embedding lookup 嵌入查找
从 KGE 组件中提取当前用户的相关 KG 嵌入和 𝑆 中的物品,这些提取的 KG 嵌入包括:
- 当前用户在 𝑆 中的 KG 嵌入$u^{KG}$;
- 𝑆 中所有物品的 KG 嵌入$S^{KG}[t],t=1,2,…$
-
personalized session embedding extraction 个性化会话嵌入提取
根据提取的 KG 嵌入计算个性化会话特定嵌入,$s^{Per}=\Theta(u^{KG},S^{KG})$。
任何现有的 SR 模型,包括现有的 PSR 模型和现有的 ASR 模式,都可以轻松插入到该框架中。
1.3 预测组件
获得个性化会话嵌入$s^{Per}$之后,预测组件可以使用它来生成下一个物品的概率分布。由于用户 KG 嵌入$u^{KG}$可以被视为用户的长期兴趣,这在许多先前的研究中已被证明对预测下一个物品很有用,从 $s^{Per}$和$u^{KG}$中获得最终会话表示$s$:

其中$||$表示连接操作,MLP(·) 是一个神经网络,它将连接的向量转换为与物品嵌入具有相同维度的向量。
为了生成下一个物品的概率分布,对于每个带有嵌入 𝒊 的物品 𝑖,计算其作为当前会话的下一个物品的分数,如下所示:

然后,使用 softmax 对 𝒛 中的分数进行归一化以获得概率分布$\hat{y}=\mathrm{Softmax}(z)$。具有 top-𝐾 概率的物品被推荐为下一个物品的候选者。
1.4 模型训练
令$y$表示下一个物品的真实概率分布,它是一个独热向量。 损失函数被定义为预测和真实情况的交叉熵:
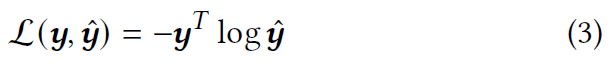
然后,包括嵌入在内的所有参数都被随机初始化,并使用小批量随机梯度下降以端到端的方式联合训练。
因此,现有的 SR 模型可以使用该框架轻松适应 SSR。 适应的社会意识模型可以提供比原始非社会意识模型甚至最先进的 SSR 模型更高的预测精度。不仅如此,进一步提出了一个实现框架 SEFrame 的模型,并且能够比这些简单的适应有更好的预测精度。
2. Social-Aware Efficient Recommender
本节中提出了一个名为 Social-aware Efficient Recommender (SERec) 的模型,它通过具体定义 KGE 和 PSE 组件来实现 SEFrame。
2.1 实现KGE组件
对于 KGE 组件的第一个任务,采用相同的方法构建第 1.1 节中描述的异构知识图。 对于 KGE 组件的第二个任务,为了学习图中称为 KG 嵌入的用户和物品节点的表示,设计了一个基于注意力机制的 HGNN,它由 𝐿 层组成。
令$H^{l}[v]$为节点$v$在第$l$层的表示,$v$可以表示用户或物品。初始节点表示$H^{0}$是用户和物品嵌入。在第$l$层 ,基于两个概念计算新的用户表示,即社会影响和用户偏好。
-
计算用户之间传递的消息以捕捉社会影响。 来自用户$u$关注的用户$v$消息被计算为$v$在$l-1$层的节点表示的线性变换:
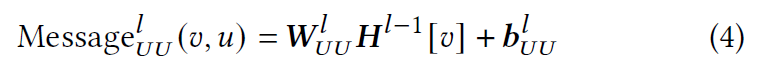
其中$W^{l}{UU}\in R^{d\times d},b{UU}^{l}\in R^{d}$是需要学习的参数。
-
计算从物品传递给用户的消息以捕获用户偏好。来自之前用户$u$之前点击物品$i$的消息计算如下:
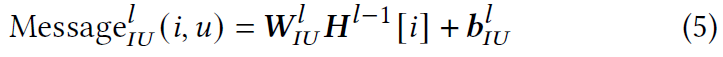
其中$W^{l}{IU}\in R^{d\times d},b{IU}^{l}\in R^{d}$是需要学习的参数。
请注意,由于考虑表示用户如何喜欢不同物品的用户偏好(或等效地,物品如何影响用户),只考虑从物品到用户的消息传递(表示物品如何影响用户),因此不需要考虑从用户到物品的消息传递(表示用户如何影响物品的点击)。
为了同时考虑社会影响和用户偏好,通常采用分层聚合方案。 具体来说,应用两种不同的聚合函数来收集来自所有相邻用户的社会影响和用户对所有相邻物品的偏好:
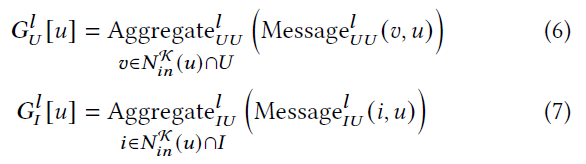
其中$N_{in}^{k}(u)$表示$K$中$u$的近邻。
然后,使用二级聚合合并来自相邻用户和物品的聚合信息:
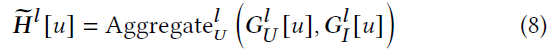
然而,这种分层聚合方案有一个问题,因为相邻用户的数量和用户的物品可能不平衡。例如,用户 $u$可能点击了很多物品,但只关注一两个用户。在这种情况下,来自相邻用户的信息是嘈杂的,而来自相邻物品的信息更可靠。为了解决这个问题,提出了注意力聚合方案,可以自动决定信任更可靠的信息源。
具体来说,直接聚合来自相邻用户和物品的消息:
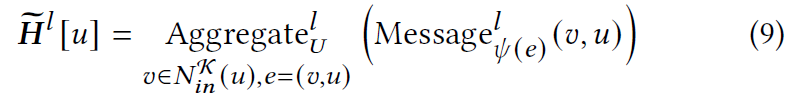
其中$\psi(e)$是边$e$的类型。
使用注意力机制定义聚合函数。 具体来说,首先计算边$e=(v,u)$传递的消息的重要性分数,如下所示:
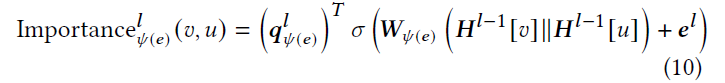
其中$q_{\psi(e)}^{l}\in R^{d},W_{\psi(e)}^{l}\in R^{d\times 2d}$是可学习的参数,$\sigma$表示sigmoid激活函数,$e^{l}\in R^{d}$是边$e$在第$l$层的特征向量。在这里,对于每一层$l$,将每条边的权重嵌入到一个密集向量中作为该边的特征向量$e^{l}$,而不是使用其原始权重值,因为边对注意力分数的影响可能不是单调的。请注意,同一条边在不同层可以具有不同的特征向量,以具有更高的建模能力。
使用 softmax 对重要性分数进行归一化以获得注意力权重:
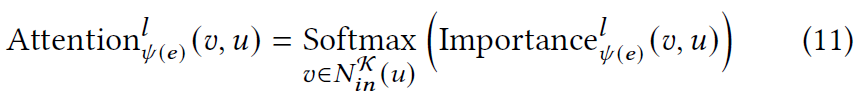
然后,来自所有相邻节点的影响被计算为所有消息的加权和:
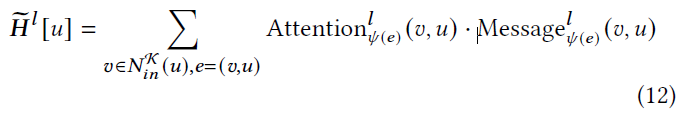
可以与用户的聚合信息类似地计算来自物品的所有相邻节点的聚合信息。 为了处理更多类型的节点和边,将聚合方案概括如下:
-
为了聚合来自目标节点$u$的所有相邻节点的信息,计算从每个相邻节点$v\in N_{in}^{K}(u)$沿边$e=(u,v)$传递的消息:
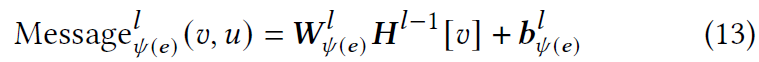
它对源节点 𝑣 的特征向量应用特定于边缘类型的线性变换,以便将来自不同节点类型的特征向量转换到相同的特征空间。
-
聚合信息$\hat{H}^{l}[u]$收集来自$N_{in}^{K}(u)$中所有邻居的消息可以使用等式 (10) 到 (13) 计算。因此,添加更多类型的节点和物品很简单。
-
根据聚合信息和旧节点表示计算新节点表示。 为此应用一个简单的特定于节点的线性变换,然后是 ReLU 激活函数:
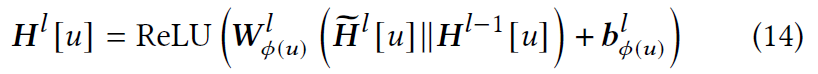
通过这种方式,为每个节点$u$在第$l$层HGNN获得了节点表示,通过堆叠$L$个这样的 HGNN 层,最终的节点表示$H^{L}$,称为 KG 嵌入,在每个节点的$L-$跳邻域中捕获高度上下文化的信息,这些信息被输入到 PSE 组件中以学习个性化的会话特定偏好。
2.2 实现PSE组件
PSE 组件的目标是在当前会话中提取当前用户的动态和个性化偏好。 为此提出了一个 GNN 模型来学习个性化的会话特定嵌入$s^{Per}$。 它涉及三个任务:
-
基于用户$u$的正在进行的会话$S$构建一个加权有向图,称为特定于会话的图$G=(V,E)$。具体来说,节点集$V$包含$S$中的唯一物品,边集$E$包含一条边$(i,j)$,如果在$S$中存在从物品$i$到物品$j$的转移。边$(i,j)$的权重,用$w_{ij}$表示,是$i\to j$在$S$中出现的次数。
-
通过在会话特定图𝐺上执行消息传递,为用户 𝑢 学习 𝑆 中每个物品的上下文特征向量,代表 𝑢 当前对物品的兴趣。 用于消息传递的 𝐺 中节点的消息内容基于 KG 嵌入进行初始化,包括物品KG 嵌入和用户 KG 嵌入,可以捕获 𝑢 对 𝑆 中物品的个性化偏好。初始消息内容由节点 𝑖 的初始特征向量建模,由$x_{i}$表示,对应于物品$S^{KG}[t]$如下:
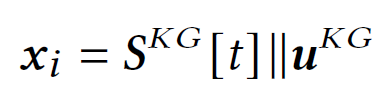
消息传递机制可以通过使用特定于会话的图 𝐺 来帮助捕获 𝑢 当前的兴趣,建模如下,令$N_{in}^{G}(i),N_{out}^{G}(i)$分别表示$G$中节点$i$的传入和传出邻居。为了学习节点$i$的上下文特征向量,从$N_{in}^{G}(i)$和$N_{out}^{G}(i)$收集信息:
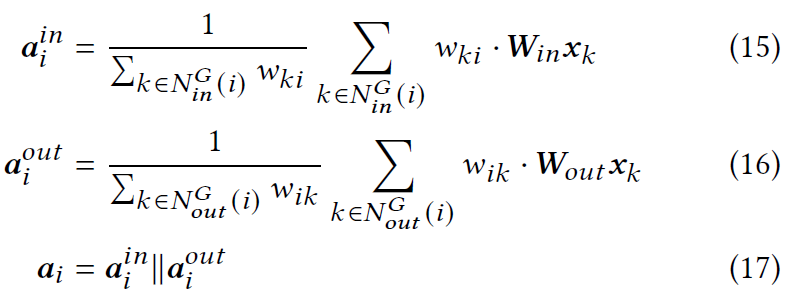
其中$W_{in},W_{out}\in R^{d\times 2d}$是需要学习的参数,$a_{i}$表示来自$i$的邻居节点的聚合信息。
然后,通过应用门控机制来合并来自相邻节点($a_{i}$)和初始特征向量($x_{i}$)的信息来获得上下文特征向量:
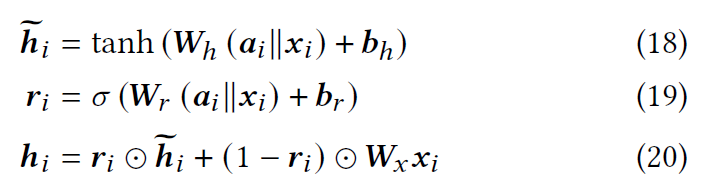
其中$W_{h},W_{r}\in R^{d\times4d},W_{x}\in R^{d\times 2d},b_{h},b_{r}\in R^{d}$是需要学习的参数,$\odot$表示逐元素乘法,$h_{i}$表示节点$i$的上下文特征向量。
-
通过使用注意力机制聚合所有节点的上下文特征向量来获得个性化的会话特定嵌入$s^{Per}$。具体来说,使用最后一个物品来选择$S$中的重要物品。令$h_{last}$表示$S$中最后一个物品的上下文特征向量。此外,由于 𝑢 的长期兴趣对于了解 𝑢 当前的关注点也很重要,因此在考虑注意力机制时也考虑了用户 KG 嵌入 $u^{KG}$。节点$i$的重要性得分定义为:
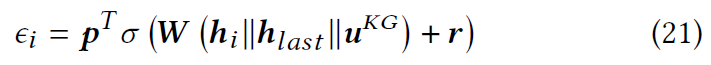
其中$p,r\in R^{d},W\in R^{d\times3d}$是需要学习的参数。
然后,个性化会话特定嵌入$s^{Per}$被计算为所有上下文特征向量的加权和:
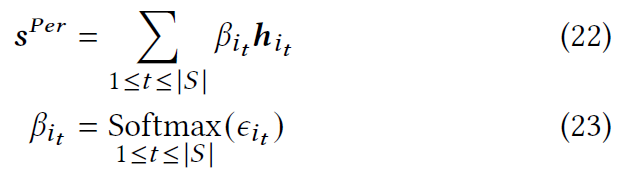
其中$i_{t}$是$S$中时间步长$t$的物品对应的节点。