MIT 6.S081/Fall 2019实验Lab: Xv6 and Unix utilities,实现Xv6下的几个常用功能函数。
接口:
int main(int argc, char *argv[])
argc:参数数量
argv:二维参数数组(字符型)需要注意,默认第一个参数
argv[0]为指令名称。
本文对思路和重要函数作分析,具体完整的实现可以查看我Github仓库上的代码.
1. sleep函数
从shell获取参数(sleep的时间),因为参数是字符串,需要通过atoi将字符串转换为数值,然后调用sleep函数执行操作。
int main(int argc, char *argv[]) {
// 判断参数数量是否符合
if (argc != 2) {
printf("Please enter only ONE INT PARAMETER!\n");
} else {
int time = atoi(argv[1]); // 将char转换为int
if (time) {
printf("Sleep time = %d\n", time);
sleep(time);
} else {
printf("Please enter An INT > 0.\n");
}
}
exit();
}
2. pingpong函数
两个进程在管道两侧来回通信。父进程通过将”ping”写入parent_fd [1]来发送子进程,而子进程则通过从parent_fd [0]读取来接收字节。子进程从父进程收到后,通过将“pong”写入child_fd [1]来回复,然后由父进程从child_fd[0]读取。
2.1 进程 pid
需要创建一个子进程,创建进程的接口为int fork(),该函数会复制父进程,从而创建一个新的进程,创建失败会返回-1。该函数调用一次会有两次返回值,在子进程中会返回0,父进程中会返回子进程的pid号,可以据此判断是父进程还是子进程,进行不同的操作。
使用示例:
int pid, child_pid, parent_pid;
// 创建子进程,判断是否创建成功
if ((pid = fork()) < 0 ) {
printf("Fork error!\n");
exit();
}
if (pid == 0) { // 子进程
child_pid = getpid();
...
} else { // 父进程
parent_pid = getpid();
...
}
可以通过getpid()获取当前的进程号。要确保子进程先退出,父进程再退出。
2.2 管道 pipe
需要创建两个管道,一个用于父进程写和子进程读,另一个用于子进程写和父进程读。创建管道的接口为int pipe(pipe_name[2]),成功返回0,不成功返回-1,正常创建后,p[1]为管道写入端,p[0]为管道读出端。
使用方法示例:
int p1[2], p2[2];
// 创建两个管道
if (pipe(p1) != 0 || pipe(p2) != 0) {
printf("Pipe failed.\n");
exit();
}
// 从p1中读入
read(p1[0], buf, sizeof(buf));
close(p1[0]); // 使用后需要关闭管道
// 写入p2
write(p2[1], "pong", 4);
close(p2[1]); // 使用后需要关闭管道
需要注意,管道read是一直阻塞的,直到管道有数据写入;如果绑定在这个管道的写端口关闭了,read返回0。需要及时关闭管道的写端,否则读出端无法判断传输是否结束。
pingpong函数实现如下:
int main(int argc, char *argv[]) {
if (argc != 1) { // 判断参数数量
printf("Please don't add any PARAMTERS!\n");
} else {
int p1[2], p2[2];
int pid, child_pid, parent_pid;
// 创建两个管道
if (pipe(p1) != 0 || pipe(p2) != 0) {
printf("Pipe failed.\n");
exit();
}
// 创建子进程
if ((pid = fork()) < 0 ) {
printf("Fork error!\n");
exit();
}
// 子进程
if (pid == 0) {
child_pid = getpid();
// 从p1[0]中读出父进程传来的ping
read(p1[0], buf, sizeof(buf));
close(p1[0]);
printf("%d: received %s\n", child_pid, buf);
// 写入p2[1]
write(p2[1], "pong", 4);
close(p2[1]);
exit();
} else { // 父进程
parent_pid = getpid();
// 写入p1[1]
write(p1[1], "ping", 4);
close(p1[1]);
// 从p2[0]中读出子进程传来的pong
read(p2[0], buf, sizeof(buf));
close(p2[0]);
printf("%d: received %s\n", parent_pid ,buf);
exit();
}
}
exit();
}
3. 素数筛选 primes
在xv6上使用管道实现“质数筛选”, 输出2~35之间的而所有质数。
筛选思路为:主进程将所有数据(例2~11)输入到管道的左侧,第一个子进程从管道读出并筛选出2,排除掉2的倍数,其他数字再写入下一管道;第二个子进程读出并筛选出3,排除掉3的倍数,其他数字写入到下一管道;第三个子进程读出筛选出5,以此类推……如下图所示:
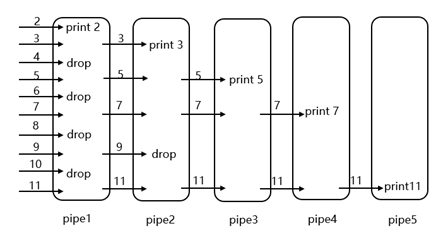
因为需要创建多个子进程和管道,但是多个进程和管道之间不会交替使用,即同一时间只有一对进程和管道在使用,所以使用一个close_pipe函数关闭使用过的pipe和进程文件。要确保子进程先退出,父进程再退出。
void my_close(int port, int pd[]) {
close(port);
dup(pd[port]);
close(pd[0]);
close(pd[1]);
}
相关函数
dup
功能为复制一个文件句柄,用法为
int dup(int handle)因为标准输入描述符总是0,并且dup函数调用总是取最小可用的数字,如果关闭0,再调用dup函数,新的文件描述符就是0了。
close
用来关闭已打开的文件,任何有关该文件描述符上的记录锁和使用该文件的进程都会被关闭和移除。用法为
int close(int fd),参数fd为open()或create()打开的文件。
每次筛选的操作在函数primes中实现,递归调用,直到筛选完所有的数。
void primes() {
int pid;
int pd[2];
int number;
// 读入管道中的第一个数,为素数
if (read(0, &number, sizeof(number))) {
printf("prime %d\n", number);
} else {
exit();
}
// 创建管道
if (pipe(pd) != 0) {
printf("Pipe failed.\n");
exit();
}
// 创建子进程
if ((pid = fork()) < 0) {
printf("Fork error!\n");
exit();
}
// 子进程筛选素数
if (pid == 0) {
my_close(1, pd); // 关闭当前子进程的文件和管道
pipe_number(number);
} else { // 父进程继续调用primes()
my_close(0, pd); // 关闭当前父进程的文件和管道
primes();
}
}
当前进程需要筛选管道中的数字,将筛选后的数字写入管道传给下一个子进程,在函数pipe_number中实现:
void pipe_number(int number) {
int recieved;
// 从管道中读出数字,写入recieved
while (read(0, &recieved, sizeof(recieved))) {
if (recieved % number != 0) { // 过滤掉能被number整除的数
write(1, &recieved, sizeof(recieved));
}
}
}
对于main函数,需要对输入进行判断,初始化输入的数字,调用primes进行筛选。
int main(int argc, char *argv) {
if (argc != 1) {
printf("Please enter No PARAMETERS.\n");
}
int pd[2];
int pid;
if (pipe(pd) != 0) {
printf("Pipe failed.\n");
exit();
}
if ((pid = fork()) < 0) {
printf("Fork error!\n");
exit();
}
if (pid == 0) { // 对子进程输入2-35
my_close(1, pd);
for (int i = 2; i <= 35; i++) {
write(1, &i, sizeof(i));
}
} else {
my_close(0, pd);
primes();
}
exit();
}
4. 文件找寻函数 find
在xv6上实现UNIX函数find(argv1 argv2),即在目录树argv1中查找名称与字符串argv2匹配的所有文件。参照user/ls.c和user/grep.c的实现逻辑。
思路为划分路径,递归处理每一步的文件夹下的所有文件,依次判断当前文件类型是文件还是文件夹,如果:
- 文件,则判断名称是否匹配,结束递归;
- 文件夹,递归进入该文件夹,继续处理;
主要函数为find(char *path, char *name),实现如下:
void find(char *path, char *name){
// from ls.c
char buf[512], *p;
int fd;
struct dirent de;
struct stat st;
// 打开当前路径的文件
if((fd = open(path, 0)) < 0){
fprintf(2, "find: cannot open %s\n", path);
return;
}
// 将文件转换为结构体
if(fstat(fd, &st) < 0){
fprintf(2, "find: cannot stat %s\n", path);
close(fd);
return;
}
// 判断当前文件类型是文件还是文件夹
switch(st.type){
case T_FILE: // 判断名字是否匹配
if(match(name, fmtname(path)))
printf("%s\n", path);
break;
case T_DIR: {
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf) {
printf("find: path too long\n");
break;
}
strcpy(buf, path);
p = buf+strlen(buf);
*p++ = '/';
// 对文件夹下的文件/文件夹依次进行判断
while(read(fd, &de, sizeof(de)) == sizeof(de)) {
if(de.inum == 0)
continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
if(stat(buf, &st) < 0){
printf("find: cannot stat %s\n", buf);
continue;
}
// avoid recursing into "." and ".."
if(strlen(de.name) == 1 && de.name[0] == '.') continue;
if(strlen(de.name) == 2 && de.name[0] == '.' && de.name[1] == '.') continue;
// 继续递归
find(buf, name);
}
break;
}
}
close(fd);
}
另一个主要函数为判断匹配函数int match(char *re, char *text),主要参考user/grep.c文件:
int match(char *re, char *text)
{
if(re[0] == '^')
return matchhere(re+1, text);
do{ // must look at empty string
if(matchhere(re, text))
return 1;
}while(*text++ != '\0');
return 0;
}
// matchhere: search for re at beginning of text
int matchhere(char *re, char *text)
{
if(re[0] == '\0')
return 1;
if(re[1] == '*')
return matchstar(re[0], re+2, text);
if(re[0] == '$' && re[1] == '\0')
return *text == '\0';
if(*text!='\0' && (re[0]=='.' || re[0]==*text))
return matchhere(re+1, text+1);
return 0;
}
// matchstar: search for c*re at beginning of text
int matchstar(int c, char *re, char *text)
{
do{ // a * matches zero or more instances
if(matchhere(re, text))
return 1;
}while(*text!='\0' && (*text++==c || c=='.'));
return 0;
}
5. xargs函数
在xv6上实现UNIX函数xargs,即从标准输入中读取行并为每行运行一个命令,且将该行作为命令的参数。
思路为依次处理每行,根据空格符和换行符分割参数,调用子进程执行指令,需要注意的是,父进程需要等待子进程执行结束后再继续处理。
int main(int argc, char *argv[]) {
char buf2[512];
char buf[32][32];
char *pass[32];
for (int i = 0; i < 32; i++) pass[i] = buf[i];
// 依次读入
for (int i = 1; i < argc; i++) strcpy(buf[i - 1], argv[i]);
// 依次处理
int n;
while ((n = read(0, buf2, sizeof(buf2))) > 0) {
int pos = argc - 1; // 参数数量
char *c = buf[pos];
// 根据空行或者换行符分割参数和指令
for (char *p = buf2; *p; p++) {
if (*p == ' ' || *p == '\n') {
*c = '\0';
pos++;
c = buf[pos];
} else *c++ = *p;
}
*c = '\0';
pos++;
pass[pos] = 0;
if (fork()) wait(); // 父进程等待子进程执行结束
else exec(pass[0], pass); // 子进程执行命令
}
if (n < 0) {
printf("xargs: read error\n");
exit();
}
exit();
}